ERGMs and Co-Offending: an Applied Social Networks Project
Illustrating the use of Exponential family of Random Graph Models
Networks
ERGM
Criminality
Author
Bernhard Bieri
Published
December 15, 2021
Introduction
This blog post constitutes the second part of the course evaluation of a social networks class I took while pursuing my masters’ in International Economics at IHEID. We have explored the process of describing a network in a previous post that you can read here. Instead, we will focus on understanding why certain patterns of ties are more likely to appear than others. Since we have cross-sectional data, we’ll use an Exponential family of Random Graph Model (ERGM).
Introducing the data
The dataset that we will use to illustrate ERGMs in this post is a cross-sectional dataset on co-offending patterns of an inner city street-gang that was observed between 2005 and 2009. The data can be accessed here under the London Gang section (Grund and Densley 2015). Let’s take a look at the data!
########################### Import data ######################################### Import adjacency matrixgangs <-as.matrix(read.csv("LONDON_GANG.csv")[,-1])# Import list of attributesgangs_attr <-read.csv("LONDON_GANG_ATTR.csv")[,-1]# Check out the dataskimr::skim(gangs_attr)
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
Age
0
1
19.83
2.69
16
18
19
21.00
27
▇▇▃▂▂
Birthplace
0
1
2.44
0.96
1
2
3
3.00
4
▃▃▁▇▂
Residence
0
1
0.37
0.49
0
0
0
1.00
1
▇▁▁▁▅
Arrests
0
1
9.91
6.44
0
5
8
14.75
23
▅▇▃▃▃
Convictions
0
1
4.20
3.66
0
1
3
7.00
13
▇▆▂▃▂
Prison
0
1
0.44
0.50
0
0
0
1.00
1
▇▁▁▁▆
Music
0
1
0.17
0.38
0
0
0
0.00
1
▇▁▁▁▂
Ranking
0
1
3.46
0.82
1
3
4
4.00
5
▁▂▅▇▁
The data is comprised of two .csv documents. The first one contains an adjacency matrix describing the co-offending patterns of two individuals in the network. The second one provides us with more information about the individual nodes in the form of different attributes, such as the age or the ethnicity (measured by birthplace) of the individuals in the network for example.
The theoretical intuition behind co-offending
A sound theoretical understanding of the theory underpinning the sociological study of criminality is required before considering network models. Without going into too much detail, one can summarize the key relevant elements in the criminal sociology literature as follows:
Co-offending patterns vary among types of crime. Co-offending is more a characteristic of juvenile than adult criminality and is often short-lived. Co-offenders tend to have many accomplices as a consequence. (Reiss Jr 1988)
Grund and Densley therefore argue that it is important to conceptualize the gang as a network to shed light into the patterns driving the organisational structure of the network, most notably the role of homophily in co-offending patterns (Grund and Densley 2012, 2015).
Note that while this list is not exhaustive by any means, it gives a sufficient overview of the theoretical framework for us to analyse the network in more detail. A more curious reader might want to read the papers by Grund and Densley on which the dataset is based and which provides an excellent overview of the literature (Grund and Densley 2012, 2015).
A primer on ERGMs
Before diving into the data analysis itself, let us remind ourselves of the key elements of the theory of ERGMs and why they are helpful in understanding the pattern of ties in this cross-sectional network. The guts of the model can be intuitively explained by looking at the components of the following function:
\(P(X=x \mid \theta)\) is the probability of observing network \(x\) conditional on the weighting parameter \(\theta\)
\(\left.\exp \left(\sum_{k} \hat{\theta}_{k}\right)\left(z_{k}(x)\right)\right)\) can be broken down into:
\(z_{k}(x)\) a vector of network characteristics such as node attributes or network properties (think homophily, transitivity, etc.)
\(\sum_{k} \hat{\theta}_{k}\) which is a vector of coefficients corresponding to the network characteristics we included in the \(z_{k}(x)\) vector.
\(\kappa\) is a normalizing constant.
However note that the normalizing constant \(\kappa\) can become very large depending on the included characteristics and the size of the network as is apparent in the following equation:
\[
\kappa=\sum_{x^{\prime} \in X} \exp \left(\sum_{k} \theta_{k} z_{k}\left(x^{\prime}\right)\right)
\] That’s a lot of networks to estimate, even if the number of vertices is relatively small! We’ll therefore use a Markov Chain Monte Carlo estimation technique which (if it behaves well) generates a stationary distribution of graphs with the right characteristics \(z_{k}\left(x^{\prime}\right)\). This process should generate a distribution with low autocorrelation (between generated networks) and provides a representative distribution of the sample space.
Finally, let us make a rapid comment about Network Linear Regression models and why they are not ideal to answer the question at hand. While they can provide insight about the impact of homophily in tie formation, they take random networks of the same size as a baseline. The main point Grund and Densley make is that the impact of adding transitivity (a measure of network structure rather than attributes) to the baseline may lead to a reduction of the pure effect of homophily in co-offending patterns. In a nutshell, omitting network structure from the baseline graphs, leads to a positive bias of homophily on co-offending due to the fact that if an individual offends with two people, it is more likely that these two co-offenders offend together as well. Since MRQAP designs cannot incorporate transitivity measures, the authors turned to ERGMs.
Getting a first look at the graph
After having gone trough this theoretical introduction, we can confidently move forward with our analysis by importing our networks in the various formats ({igraph}, {tidygraph}, and {network}), visualizing it and describing the main features of the network. Note that a particular focus will be given on exploring homophily due to the theoretical considerations laid out above. Note that for the analytical purposes, we have generated a vector of random names and named the different vertices, these names are not in the original dataset! Finally, note that the authors have removed 6 nodes from the original network which we were not able to identify. This will lead to different results in the analytical part where we run the ERGMs and try to replicate their findings.
Homophily in Criminal Networks in 2D (hover over me!)
Homophily in Criminal Networks in 3D (turn me!)
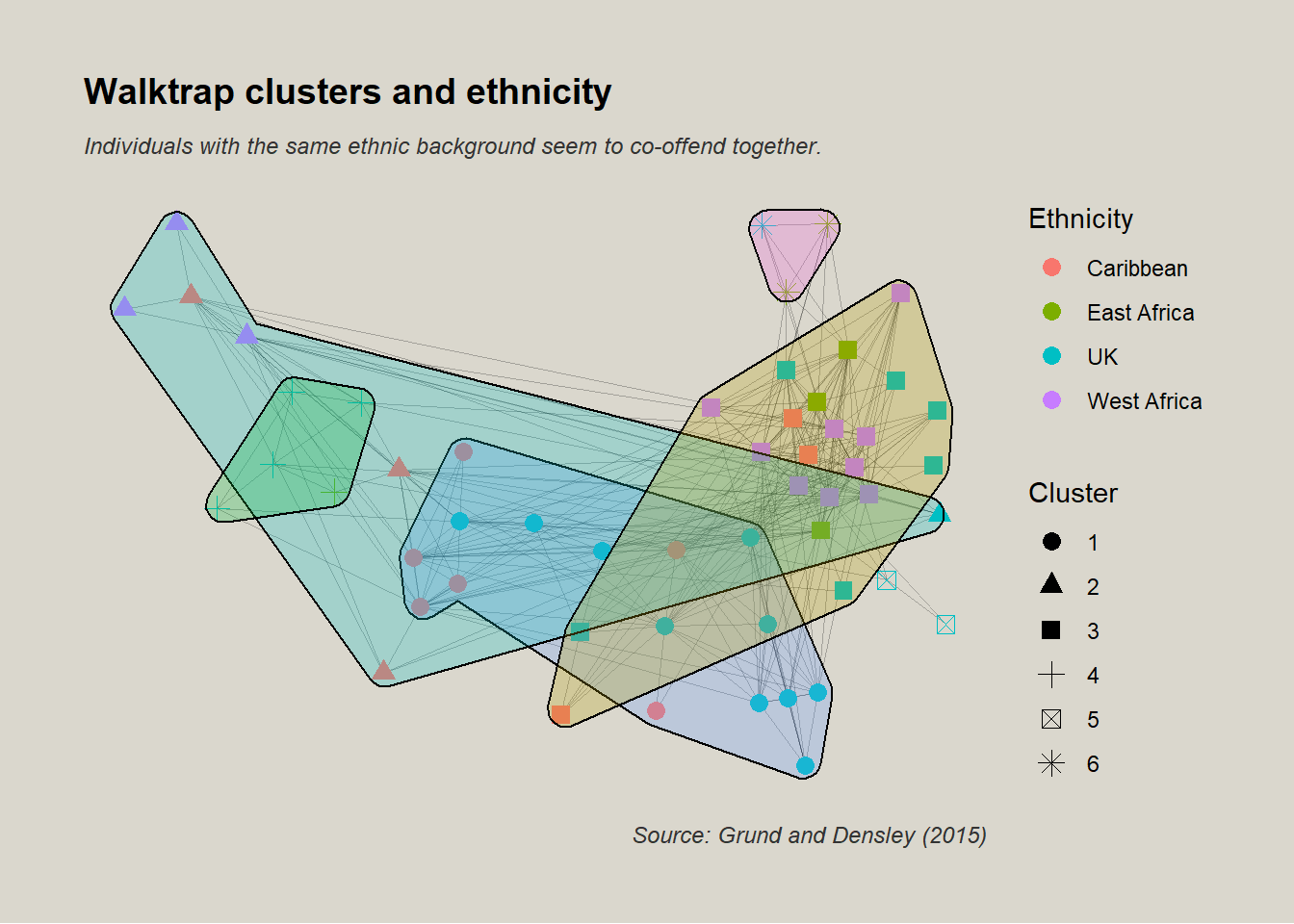
Just like the authors (Grund and Densley 2015), we observe a certain level of homophily along ethnic lines. In other words, individuals in this network, seem to tend to co-offend more frequently with members of the same origin.
Laying out the hypotheses and taking a closer look at homophily
Before moving to the inferential analysis with an ERGM, let us investigate the role of homophily in the network beyond the simple visual inspection above (Grund and Densley 2015). We will therefore start by looking at the three central hypothesis that we will try to test with the ERGM models (Grund and Densley 2015):
“Gang members are more likely to offend with each other when they have the same ethnic background.”
“Triad closure accounts for some ethnic homogeneity in co-offending in gangs.”
“Gang members are even more likely to offend with each other when they have the same ethnic background AND share another co-offender from the same ethnic background.”
In the following graph, we see that walktrap clustering seems indeed to be happening along ethnic lines again. At this point we could run an MRQAP or network linear regression but as explained at the end of the theoretical part above, the main point of the authors is to show that the structure of the network biases naive estimates of homophily. Thus we’ll move onto the more elaborate ERGM models.
Running the Exponential family Random Graph Model (ERGM)
On table 2 (p.362) of the paper, the authors present four ERGM models that can be summarized in term of included RHS network characteristics as follows:
Model 1: Edge count and homophily (ethnicity)
Model 2: Edge count, homophily (ethnicity), and triadic closure (GWESP, fixed decay parameter at 0)
Model 3: Edge count, homophily (ethnicity), triadic closure (GWESP, fixed decay parameter at 0), and ethnicity dummies
Model 4: Edge count, homophily (ethnicity), triadic closure (GWESP, fixed decay parameter at 0), ethnicity dummies and a custom interaction term between triadic closure and homophily computed using simulations.
The present post focuses essentially on the first three models which correspond to the second, third and fourth model in the table below. We simply added an additional “super naive model” containing only an edge count on the RHS as our first model. We report and interpret goodness of fit statistics on the third model below. Finally note that we will unfortunately not get the exact same results as the authors since their sample only contains 48 individuals instead of the full 54 they include in the dataset.
To get familiar with the coefficient interpretation, let us start by considering the naive model where we only included an edge count on the RHS of the ERGM. As we saw above, we need to transform the edge coefficient slightly before interpreting it since the reported coefficients are conditional log-odds of the existence of a tie. This process is similar to the interpretation of logit models. Following the transformation (outlined in the code below), we can interpret the coefficient as adding one more tie changes the log-odds (conditional on all other parameters) of the presence of a tie by \(0.22\). Unsurprisingly, we see that the coefficient corresponds to the density of the network (i.e. the proportion of potential ties that are actually present in the graph). In our case, we would interpret this coefficient as the “constant” of our regression model.
Untransformed
Transformed
Density
edges
-1.264933
0.2201258
0.2201258
Now that we know how to interpret the coefficients, it is time to look at the goodness of fit (GOF) measures that run simulations and show us how well our model captures the characteristics of the observed network. We start by taking a visual comparison between the observed network and a simulation. We immediately note that the observed network is much denser and does not capture the characteristics of our observed network very well.
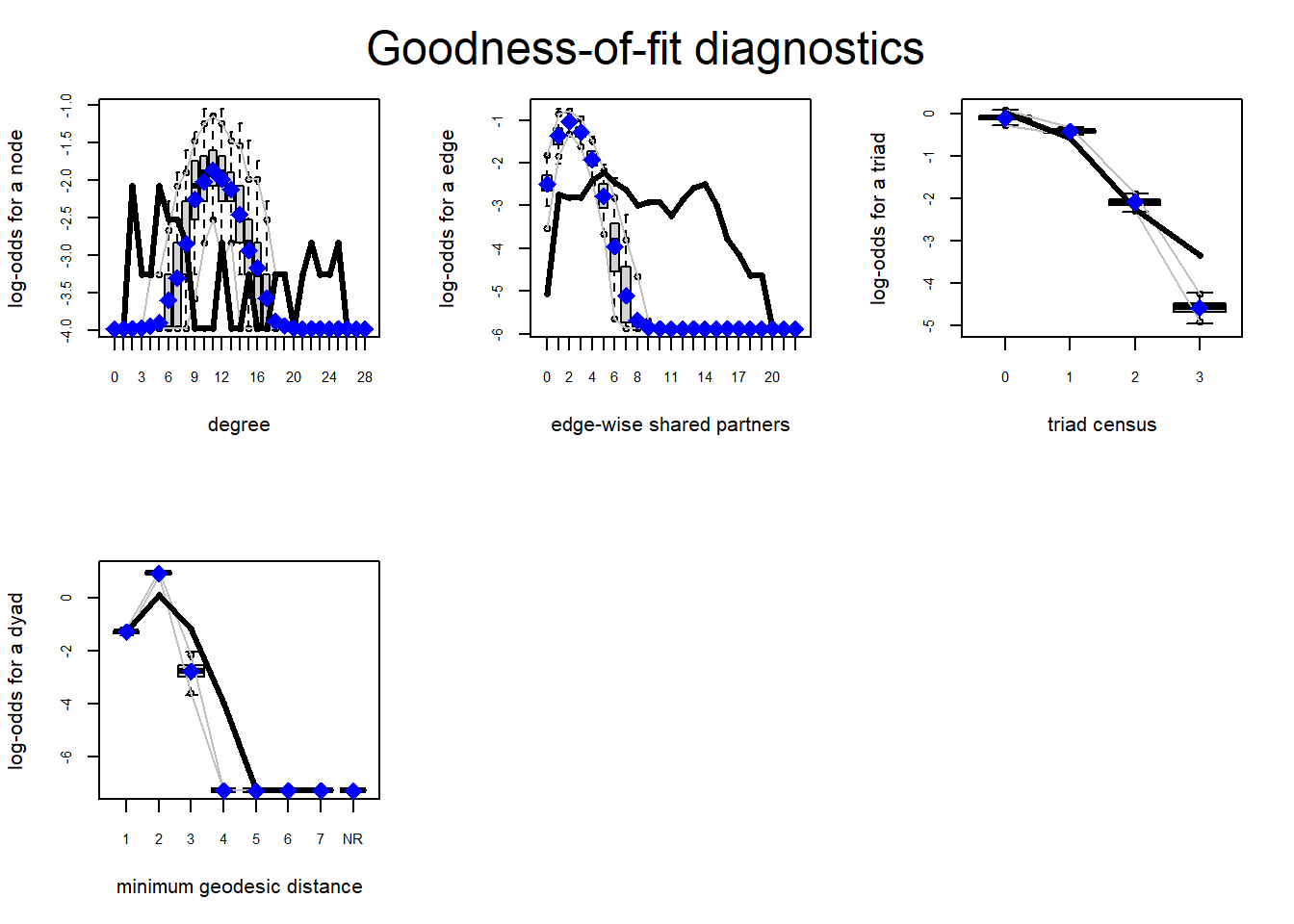
After getting this visual intuition, we proceed to check the GOF quantitatively. Thankfully, the {ergm} package has a nifty function that automates the simulations and returns some key metrics that we can use to decide whether our model fits the data. In this case, the results confirm the visual inspection we did above. We compare the first moment estimates of the simulated networks (in blue) with the actual observed value (in black) in every graph. Simply put, a good fit is indicated by an overlap of the two lines. We are thus underestimating low and high degrees and overestimating medium ones. Furthermore, low edge-wise shared partners seem to be overestimated while high ones are underestimated. The triad census measure seems to be underestimated for 0 closure and 2 and overestimated for 1 and 3. All in all, we see that our naive model is not a very good fit at all!
Let us therefore proceed to estimate the more complex models that the authors suggest (Grund and Densley 2015) to see whether more complex structural elements are at play here. We will interpret the various models in the following lines before turning to the GOF diagnostics in the next section. Consistent with the authors, we see that homophily plays a significant role in the tie formation process/co-offending in all three specifications. Having a positive coefficient here implies that individuals tend to co-offend with others of the same ethnicity, confirming earlier results of the authors (Grund and Densley 2012). This confirms the first hypothesis we laid out above. Secondly, we see that triad closure defined as a GWESP measure with zero decay. positively impacts the probability of a tie and is significant throughout the specifications. This implies that if an individual offends with two others, the latter are more likely to offend together. Note that this result does not allow us to confirm the second hypothesis of the authors since the point estimate of the homophily coefficient does not change. This in turn is likely a factor of considering the full sample where they only considered 48 out of the 54 individuals in the paper. The third and final specification contains attribute dummies to account for “ethnic group effects” (note that the baseline category is West Africa). Adding these effects reinforces both the triad closure and the homophily coefficient. Finally, note that we cannot confirm or deny the third hypothesis we laid out above since we were not able to replicate the creation of the new interaction statistic between triad closure and homophily. AIC and BIC both indicate that the last model has the lowest prediction error f the four. We will therefore move forward by considering this model in the GOF checks.
ERGM results table
Naive Model
Model 1
Model 2
Model 3
Edges
-1.26***
-1.38***
-3.95***
-3.23***
(0.06)
(0.08)
(0.66)
(0.73)
Nodematch(Ethnicity)
0.36***
0.34**
0.76***
(0.14)
(0.13)
(0.14)
GWESP(decay = 0)
2.32***
2.30***
(0.64)
(0.70)
Carribean
-0.28**
(0.13)
U.K.
-0.81***
(0.11)
East Africa
0.01
(0.16)
AIC
1510.47
1505.66
1479.23
1425.89
BIC
1515.73
1516.19
1495.03
1457.49
Log Likelihood
-754.23
-750.83
-736.62
-706.94
***p < 0.01; **p < 0.05; *p < 0.1
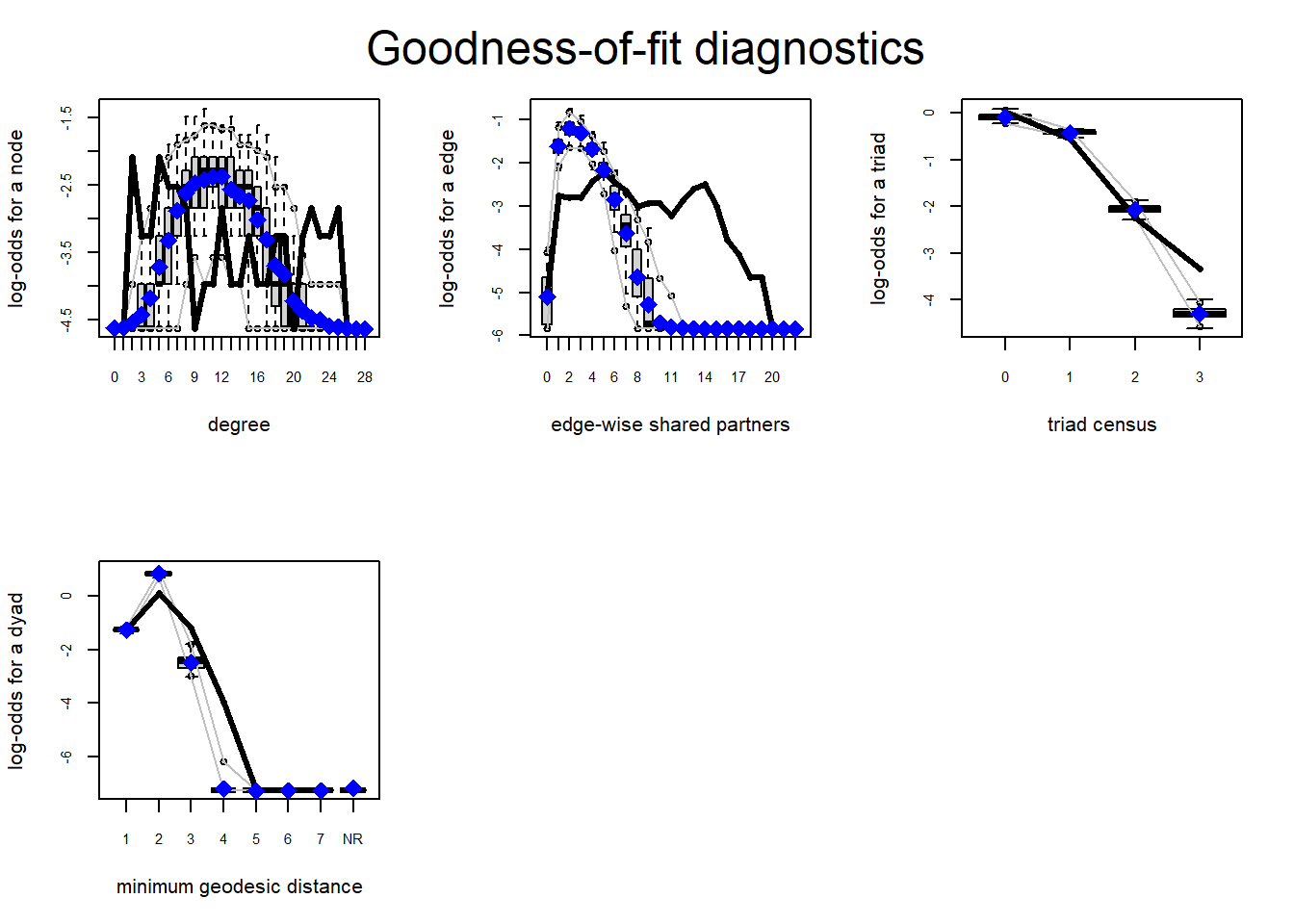
The GOF checks for the third model still indicate that we could do better to fit the model to the observed data as we underestimate low and high degrees and overestimate middle ones. The edge-wise shared partner simulations still overestimate low values and underestimate high ones. Triad census values are better for 0 and 1 but worse for 3 and 4. It is therefore necessary to stress that the authors have reported better GOF estimates for their fourth model which we were not able to compute (see Grund and Densley (2015) p.363).
Conclusion
The main goal of this lengthy post was to walk the reader through an ERGM analysis by providing a practical example in the form of a replication attempt of a paper on the impact of ethnic homophily and triad closure on co-offending patterns (Grund and Densley 2015). We were able to replicate part of the paper and confirm the first hypothesis of the authors as well as infer that triad closure has a significant effect on these tie patterns. Note that we were unfortunately not able to replicate the fourth model the authors estimated nor were we able to determine which 6 nodes were taken out of the sample. This leads our results to be somewhat disappointing. Interesting avenues for further research in the area would include the creation of a panel or time series dataset which would allow us to apply new models such as stochastic actor oriented models or DyNAMs to uncover the dynamic nature of co-offending patterns.
Appendix
########################### Set chunk options ##################################knitr::opts_chunk$set(eval =TRUE,echo =FALSE,fig.align ="center",# out.width = "95%",fig.path ="static" )########################### Load packages ######################################rm(list =ls())# install.packages(librarian) # If necessarypkgs <-c("tidyverse", "randomNames","igraph", "skimr", "ergm", "sna","coda", "latticeExtra", "texreg","manynet", "oaqc", "concaveman")# library(migraph)librarian::shelf(pkgs)# Set seed for replicability:set.seed(2193)########################### Import data ######################################### Import adjacency matrixgangs <-as.matrix(read.csv("LONDON_GANG.csv")[,-1])# Import list of attributesgangs_attr <-read.csv("LONDON_GANG_ATTR.csv")[,-1]# Check out the dataskimr::skim(gangs_attr)########################### Create graph ######################################## Create igraph object:netigraph <- manynet::as_igraph(gangs)# Generate random namesgen.names <-function(n, ...){ names <-unique(randomNames::randomNames(n = n, ...)) need <- n -length(names)while (need >0) { names <-unique(c(randomNames::randomNames(n = need, ...), names)) need <- n -length(names) }return(names)}gangmemnames <-gen.names(ncol(gangs), which.names ="first")gangs_attr$ethnicity <- dplyr::if_else(gangs_attr$Birthplace ==1, "West Africa", dplyr::if_else(gangs_attr$Birthplace ==2, "Caribbean", dplyr::if_else(gangs_attr$Birthplace ==3, "UK","East Africa")))# Add attributes to the networkV(netigraph)$name <- gangmemnamesnetigraph <- netigraph %>% igraph::set.vertex.attribute(name ="age", value = gangs_attr$Age) %>% igraph::set.vertex.attribute(name ="birthplace", value = gangs_attr$Birthplace) %>% igraph::set.vertex.attribute(name ="ethnicity", value = gangs_attr$ethnicity) %>% igraph::set.vertex.attribute(name ="residence", value = gangs_attr$Residence) %>% igraph::set.vertex.attribute(name ="arrests", value = gangs_attr$Arrests) %>% igraph::set.vertex.attribute(name ="convictions", value = gangs_attr$Convictions) %>% igraph::set.vertex.attribute(name ="prison", value = gangs_attr$Prison) %>% igraph::set.vertex.attribute(name ="music", value = gangs_attr$Music) %>% igraph::set.vertex.attribute(name ="ranking", value = gangs_attr$Ranking)## Notes related to the definition of the vertex attributes: ### - Age of the individual# - Birthplace of the individual:# - 1 = West Africa# - 2 = Caribbean# - 3 = UK# - 4 = East Africa# - Residence: Dummy# - Arrests: Number of arrests# - Conviction: Number of convictions# - Prison: Dummy Has been to prison?# - Music: Likes music# - Ranking: Dummy## Notes related to the definition of the edge attributes: ### - 1 (hang out together)# - 2 (co-offend together)# - 3 (co-offend together, serious crime)# - 4 (co-offend together, serious crime, kin)## Convert to other formats for further processing### {tidygraph} for pretty vizualisationsnettidy <- manynet::as_tidygraph(netigraph)# {network} for running ERGMsnetnetwork <- manynet::as_network(netigraph)########################## Initial Visualizations ############################### With networkD3# Convert to networkD3 consistent objectnetnetd3 <- networkD3::igraph_to_networkD3(netigraph,group =V(netigraph)$ethnicity)# Add node size attribute as the number of arrestsnetnetd3$nodes$size <-V(netigraph)$arrests# RendernetworkD3::forceNetwork(Links = netnetd3$links,Nodes = netnetd3$nodes,Source ='source',Target ='target',NodeID ='name',Group ='group',Nodesize ='size',colourScale = networkD3::JS("d3.scaleOrdinal(d3.schemeCategory10);"),linkDistance =75,fontSize =18,legend =TRUE,opacity =0.8)# With threejs# Step 1 Define a palette:pal <- iheiddown::iheid_palette("SDGs", length(unique(V(netigraph)$ethnicity)))netthreejs <- netigraph%>% igraph::set.vertex.attribute(name ="size", value = gangs_attr$Arrests/3) %>% igraph::set.vertex.attribute(name ="color",value = pal[vertex_attr(netigraph, "birthplace")])# Renderthreejs::graphjs(netthreejs,layout = igraph::layout_with_fr(netthreejs,dim =3),bg ="#DAD7CD")# Graph Density:density <- migraph::graph_density(netigraph)# 0.2201258# Compute the Blau Index# Definition:# Probability that two entities taken at random from the dataset of interest# (with replacement) represent the same type# This index reaches its minimum value (0) when there is no variety,# that is to say, when all individuals are classified in the same category.# Since the index is normalized to the 0 to 1 range, when equal to 1 it means# that there is certainty of observing the same attribute value when taking# two nodes at randomblauEthnicity <- migraph::graph_blau_index(netigraph, "ethnicity") # 0.691358# Are certain groups more diverse than others?nettidy <- nettidy %>%mutate(wt_group =membership(cluster_walktrap(nettidy)))lbb <- graphlayouts::layout_as_backbone(nettidy)pal1 <- iheiddown::iheid_palette("SDGs",length(unique(membership(cluster_walktrap(nettidy)))))# Graphicallyggraph::ggraph(nettidy,layout ="manual",x = lbb$xy[, 1],y = lbb$xy[, 2]) + ggraph::geom_edge_link0(col =0, width =0.2, alpha =0.25) + ggraph::geom_node_point(aes(color = ethnicity,shape =as.factor(membership(cluster_walktrap(nettidy)))),size =3) + ggforce::geom_mark_hull(aes(x, y,group =membership(cluster_walktrap(nettidy)),fill = pal1[membership(cluster_walktrap(nettidy))]),concavity =4,expand =unit(2, "mm"),alpha =0.25,show.legend =FALSE) + ggplot2::labs(color ="Ethnicity",shape ="Cluster",title ="Walktrap clusters and ethnicity",subtitle ="Individuals with the same ethnic background seem to co-offend together.",caption ="Source: Grund and Densley (2015)") + ggraph::theme_graph() + ggplot2::theme(plot.caption =element_text(color ="grey20",face ="italic"),plot.title =element_text(size =14),plot.subtitle =element_text(color ="grey20",face ="italic",size =9),plot.background =element_rect(fill ="#DAD7CD"))# Quantitatively: <- Blau Index within a clusterblaucluster <- migraph::graph_blau_index(nettidy,"ethnicity","wt_group")# Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 # 0.4687500 0.6122449 0.6938776 0.3200000 0.0000000 0.4444444# Small cluster####### Model 1: Standard ERGM with only an edgecount -> our baseline ##########ergm1 <- ergm::ergm(netnetwork ~ edges)# Log-likelihoodergm1mle <- ergm1$mle.lik# Coefficientscoefs1 <-data.frame(ergm1$coefficients,exp(ergm1$coefficients) / (1+exp(ergm1$coefficients)), migraph::graph_density(netigraph))colnames(coefs1) <-c("Untransformed", "Transformed", "Density")knitr::kable(coefs1)# Coefficients have to be reexpressed as the conditional log-odd of a tie# occurring. In this case it is equivalent to the density by construction.# Goodness of fit of the model -> is it a good model?# Let's look at it visually:ergm1.sim <-simulate(ergm1)par(mfrow =c(1,2)) # This command enables side-by-side comparison.plot(netnetwork, main ="Observed")plot(ergm1.sim, main ="Simulated")par(mfrow =c(1,1))# Mhh one can spot differences between the two graphs, the simulated one being# more dense than the observed network. Let's use the `statnet::gof()` function# to get more advanced diagnostics.ergm1.gof <-gof(ergm1, GOF =~ degree + triadcensus + espartners+ distance - model)par(mfrow =c(2,3))plot(ergm1.gof, plotlogodds = T)par(mfrow =c(1,1))# Goodness of fit measures of *non-included* network level, node level or dyad# level measures.# We look at this after running our model and checking whether the MCMC generated# networks have indeed the same characteristics than the one we observe.## One test of whether a local model “fits the data” is therefore how well it# reproduces the observed global# network properties that are not in the model. We do this by choosing a# network statistic that is not in the# model, and comparing the value of this statistic observed in the original # network to the distribution of values# we get in simulated networks from our model, using the gof function.# The gof function is a bit different than the summary, ergm, and simulate# functions, in that it currently# only takes 3 ergm-terms as arguments: degree, esp (edgewise share partners),# and distance (geodesic distances).# Each of these terms captures an aggregate network distribution, at either# the node level (degree), the edge# level (esp), or the dyad level (distance).# # From page 32 of the EGRM package manual.# # Conclusion, our simple model is really not a good fit! We are underestimating# low and high degrees and over estimating medium ones. Furthermore, low# edge-wise shared partners seem to be overestimated while high ones are# underestimated. The triad census measure seems to be underestimated for 0# closure and 2 and overestimated for 1 and 3. All in all, we see that our# baseline model is not a good fit! Let's try to follow the Grund and Dempsey# to see the result of their model specification.# Models p.362 paper# IMPORTANT: the network they consider in their 2015 paper is missing 6# individuals (no reason was mentioned in the paper). Since we can't# infer which individuals were removed from the network, we will not get the# same results as the authors. Hopefully though, this will not impact# the interpretation too much. Let's estimate away!# Model 1ergm2 <- ergm::ergm(netnetwork ~ edges +nodematch("ethnicity"))coefs2 <- ergm2$coefficients# Model 2ergm3 <- ergm::ergm(netnetwork ~ edges +nodematch("ethnicity") +gwesp(0, fixed =TRUE))coefs3 <- ergm3$coefficients# Model 3ergm4 <- ergm::ergm(netnetwork ~ edges +nodematch("ethnicity") +gwesp(0, fixed =TRUE) +nodefactor("birthplace"))coefs4 <- ergm4$coefficients# Getting the results from model 3 into a table:texreg::knitreg(list(ergm1, ergm2, ergm3, ergm4),center =TRUE,caption ="ERGM results table",custom.coef.names =c("Edges", "Nodematch(Ethnicity)","GWESP(decay = 0)", "Carribean", "U.K.","East Africa"),custom.model.names =c("Naive Model", "Model 1", "Model 2","Model 3"),stars =c(0.01, 0.05, 0.10))# Goodness of fit: -----# The authors only provide information of the goodness of fit check for the# fourth model. Since we don't compute it here, we'll simply do the GOF on the# third model.# Model 3: GOFergm4.gof <- ergm::gof(ergm4,GOF =~ degree + triadcensus + espartners + distance - model)par(mfrow =c(2,3))plot(ergm4.gof, plotlogodds = T) # Add the argument "plotlogodds=T" here to rescalepar(mfrow =c(1,1))################################## Citing all loaded packages ################################### knitr::write_bib(c(.packages(), "blogdown"), "packages.bib")
Grund, Thomas U, and James A Densley. 2012. “Ethnic Heterogeneity in the Activity and Structure of a Black Street Gang.”European Journal of Criminology 9 (4): 388–406.
———. 2015. “Ethnic Homophily and Triad Closure: Mapping Internal Gang Structure Using Exponential Random Graph Models.”Journal of Contemporary Criminal Justice 31 (3): 354–70.
Papachristos, Andrew V, David M Hureau, and Anthony A Braga. 2013. “The Corner and the Crew: The Influence of Geography and Social Networks on Gang Violence.”American Sociological Review 78 (3): 417–47.
Reiss Jr, Albert J. 1988. “Co-Offending and Criminal Careers.”Crime and Justice 10: 117–70.
Wasserman, Stanley, Katherine Faust, et al. 1994. “Social Network Analysis: Methods and Applications.”